BootCaT front-end tutorial - Part 4
Editing the URL list
In this step you can choose to remove URLs you think might not be interesting. Just for fun try unchecking the box next to a couple of URLs: notice how the number of “Selected URLs” changes when you check/uncheck the boxes. You can also click on the URLs to visit the web page and decide whether you want to include the page in your corpus or not.
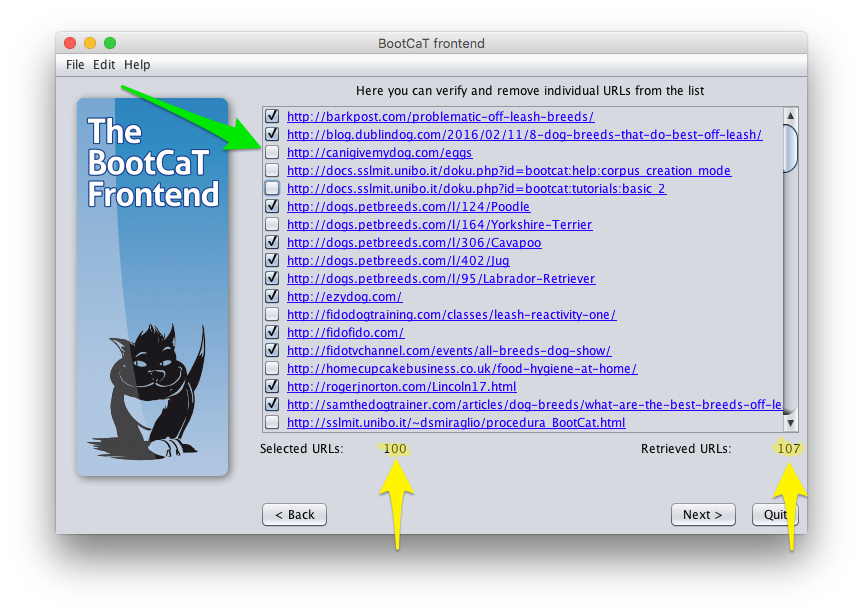
 Notice how the number of “Retrieved URLs” appears to be wrong: we generated 15 queries and instructed BootCaT to retrieve 10 URLs per query, so the total should be 150. What happened then? Simple, quite a few URLs where retrieved more than once (this is because the queries can be very similar to one another, as the tuples overlap to a large extent) and duplicates were automatically eliminated by BootCaT.
Notice how the number of “Retrieved URLs” appears to be wrong: we generated 15 queries and instructed BootCaT to retrieve 10 URLs per query, so the total should be 150. What happened then? Simple, quite a few URLs where retrieved more than once (this is because the queries can be very similar to one another, as the tuples overlap to a large extent) and duplicates were automatically eliminated by BootCaT.
Click “Next”.
Building the corpus
This is the final step.
Not only will the pages be downloaded, they will also be automatically cleaned:
- HTML code will be removed
- boilerplate (i.e. things like menus, navigation bars, ads, disclaimers, automatic error messages) will be stripped
The purpose of this stage is to get rid of elements which are part of the downloaded web pages, but that are very unlikely to be of interest to corpus users. However, since this process is automated, the cleaning process is far from perfect, so be aware that some unwanted elements will still be present in the corpus.
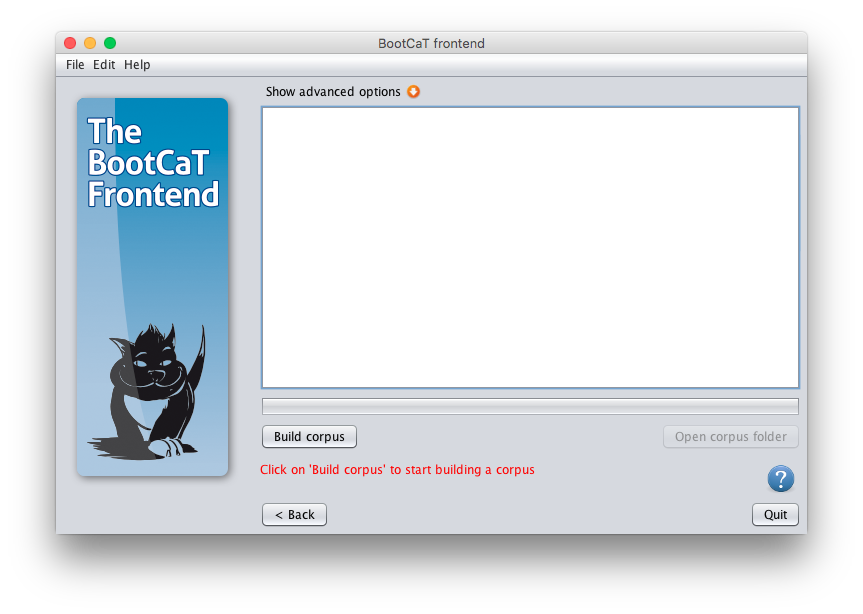
Click on “Build corpus” to start the corpus creation process. This will take a while, depending on Internet traffic, connection speed and number of URLs to download.
Go make a cup of tea while you wait.
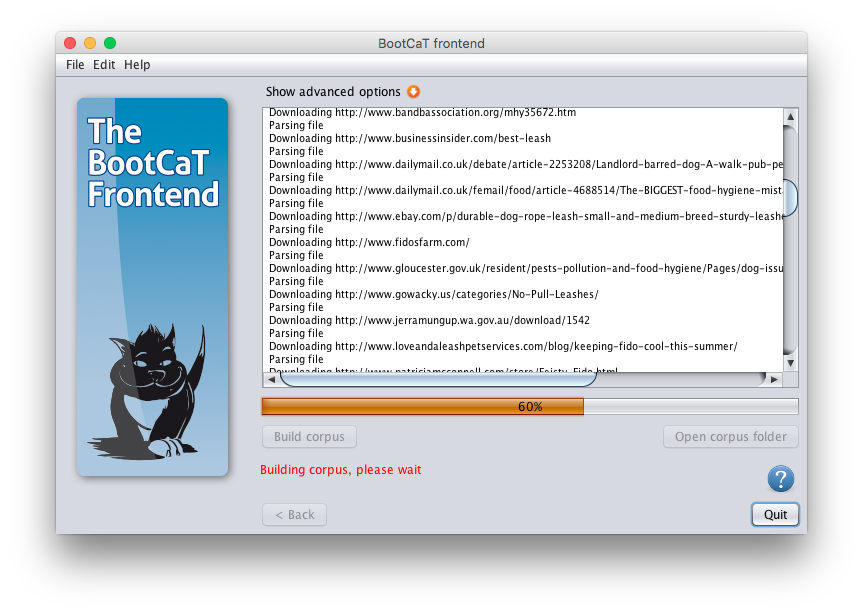
Once the download is complete click “Open corpus folder”.
The contents of the folder where the corpus data is stored will be displayed.